Issue
The partition key is the concept of defining uniqueness and improving performance. Most databases with large amounts of data or frequently accessed data should have certain unique and categorical information defined. This information will help read or update the data in bulk. However, this information is very lightly taken, and most clients complain about higher data consumption or unusable categorization of data resulting in higher transactions. Both scenarios can add a significant cloud costs if managed incorrectly. I have had an experience where there was no unique information defined for many containers in COSMOS DB. It was frequently accessed, thus the client paid thousands of dollars in transactions. They also experienced latency issues getting data from several containers, resulting in poor application performance.
Solution
Azure recommends certain practices to create a partition key. In addition, there are key points to consider when defining a partition key. But before we talk about partition keys, it is essential to understand the types of partitions and their significance.
Types of Partitions
Partitioning in Azure Cosmos DB is used to divide and categorize similar items into different containers called partitions. This approach gives the system flexibility and the ability to maintain and scale as required systemically. Also, it provides a streamlined approach to querying and using data within the application.
There are two types of partitions: 1) Logical Partitions and 2) Physical Partitions.
Logical Partition
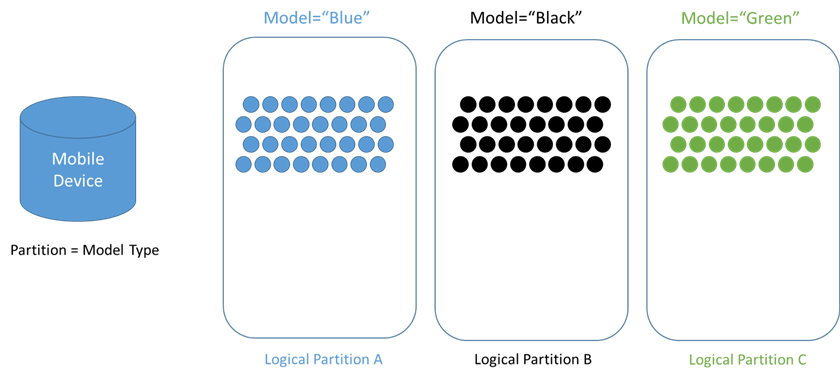
A Logical Partition is a partition where a set of items has the same partition key. In other words, this partition is created based on what data category we would like to look at. Let's use the example of car manufacturing. What if we select the cars to be partitioned by car brand type (Ferrari, Ford, Honda, Mercedes, etc.)? This might be a good choice, but it also might not be. A point to remember is that we should choose a partition that never changes. The simple reason is to define a set/subset which can be grouped logically that will have the same type of actions performed. Defining a logical partition is a key design decision for the partition key.
A logical partition can grow up to 20GB and have a throughput limit of 10,000 Request Units (RU) per second. This is limited because each logical partition is mapped to a "Physical Partition", and each Physical Partition can only have a maximum of 10,000 RUs.
Physical Partition
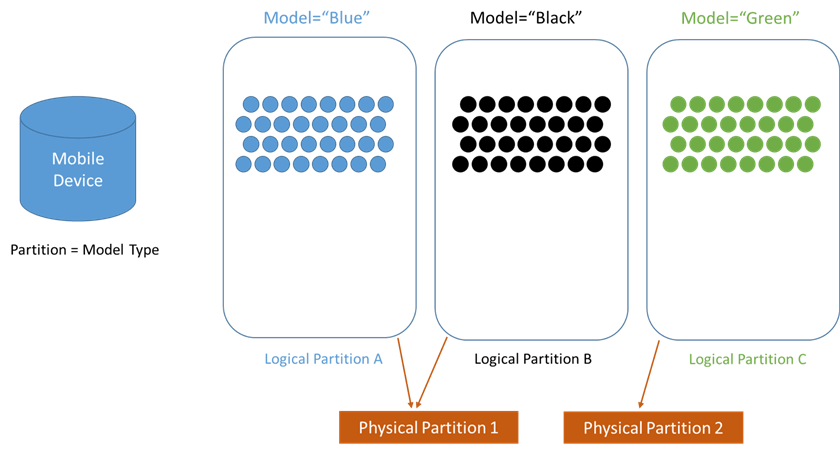
Azure Cosmos DB scales containers by distributing data in multiple physical partitions. Azure Cosmos DB completely manages physical partitions. Usually, it is scaled automatically. One or more logical partitions can be mapped to a single partition. So, it is correct to say, "One physical partition can have one or more Logical partitions, but one Logical partition will always be mapped to one and only one Physical Partition."
There is no limit to the number of physical partitions; however, one single physical partition can only be a maximum of 50GB. Also, as stated earlier, each partition can have a throughput of 10,000 RUs per second max. In case the limit of storage increases to more than 50GB, the system will automatically scale and create a new partition. Azure uses hash-based partitioning to partition logical partitions across the physical partitions. Thus, all the logic mappings to the physical partition will also be automatically mapped.
Defining a Partition Key
Now that we have a fair understanding of partitions, let's discuss the best practices and considerations for defining a partition key.
There are three main factors to consider: 1) uniformity, 2) uniqueness, and 3) distinctness.
Uniformity - Even Distribution
Below are two examples of even and uneven storage distribution:
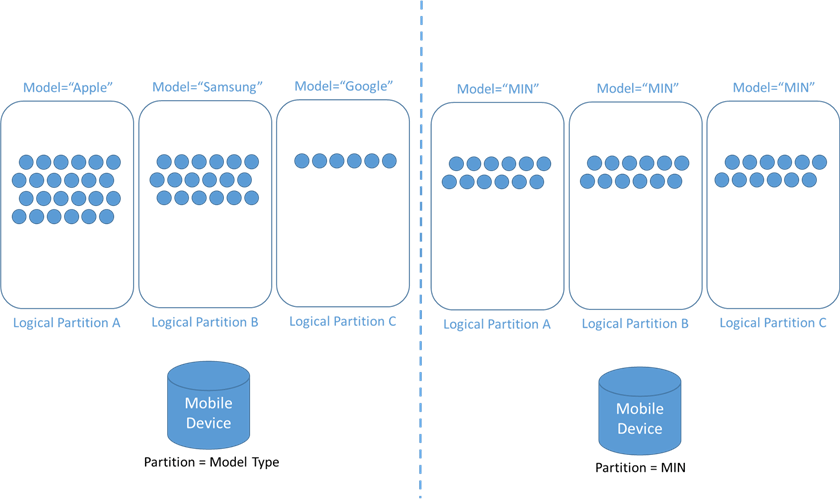
As we know, logical partitions are made up of partition keys. The example above shows the sales of mobile devices. On the left, we can see that the partition key was kept as "model type", which leads to containers like Apple, Samsung, and Google (and more).
However, the challenge is that Apple and Samsung have much higher sales than Google. This may also be called "Hot Partitions". Again, this type of container will change if we further drill down into the containers as per the location database. This will result in uneven data distribution in containers, which may lead to latency and limit throughput utilization. For example, I want to get information about a device, but since the partitions are not evenly distributed, it will result in higher throughput and, in return, higher costs to the customer.
Thus, it would be much preferable to use a partition key like "Mobile Identification Number (MIN)", which will help distribute data evenly in logical and physical partitions.
Uniqueness – High Cardinality
A partition key with high cardinality will result in better distribution and scalability of data. Below are two examples of high and low cardinality:
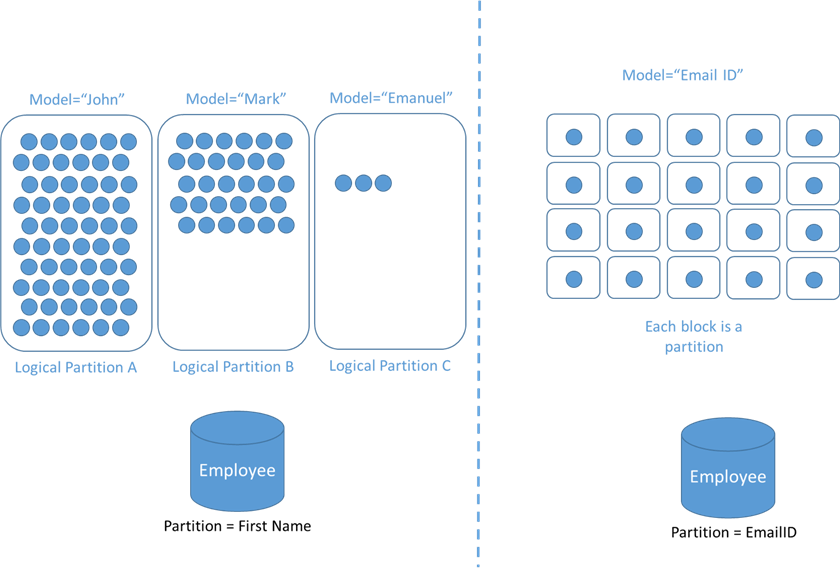
The image on the left shows that we have a database full of users where the partition key has been defined as "First Name". Now, it is very likely there are many first names like "John" or "Mark". If the partitions are made based on first names, they produce uneven and less functional partitions.
Instead of first name, let's say we define the partition key as "email address", which is usually unique to each user, and in this way, it ensures that each item has a unique identifier. This will create uniform partitions at scaling times and have an even distribution of logical partitions in containers.
Distinctness – Spread Request Units
A partition key must also be created considering the spread of the request unit's distinctness. In other words, a partition key should not result in a logical partition turning into a hot partition at any given time. Below is one example showing hot partitions due to lack of distinctness.
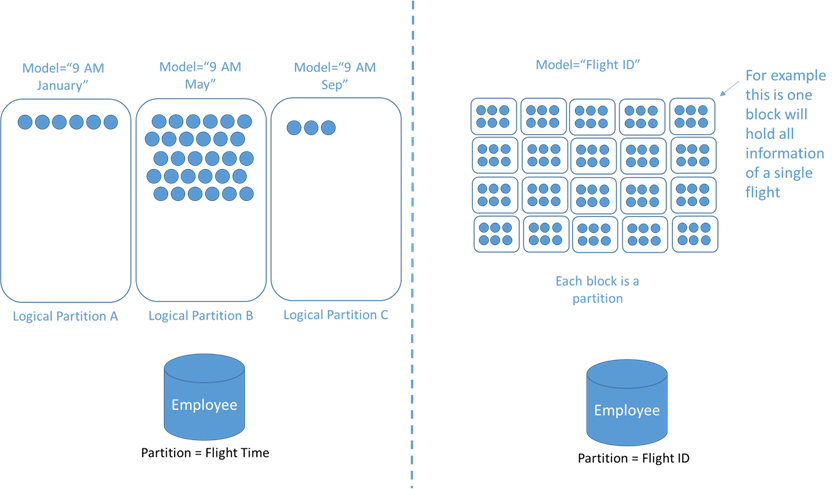
The above example shows the airport landing data stored in a database. In the image, the partition key used is "Flight time". Now we know several factors affect an increase in the landing zone time. It is possible that some heavy Boeing flights may come early during the normal season but is usually late during holidays and in harsh weather seasons like winter/monsoon. This kind of distribution will neither give even distribution nor provide any uniqueness to perform deep analysis. Instead, it will end up creating complex normalization and analysis processes. A better partition key could be "Flight Identification No", which is unique to each flight. Even if the flight changes, the identification will still be applicable and can be easily used to track the data.
Thus, these three factors help to understand and design partition keys to distribute Azure Cosmos DB data.
There are also a few considerations to think about:
- In the case of heavy-duty read data, the partition key can be defined on the metadata, which is used for most filtering in queries. For example, an employee database would ideally be partitioned using the employee ID. But sometimes, organizations also have an employee code that is more frequently used than the ID. In such cases, it is better to use the employee code, which will help to query faster and index the items.
- Synthetic keys are also good practice when defining partition keys. A synthetic key is a key that is either created using multiple metadata (like ItemID + Employee ID) or keys using prefixes or suffixes ("ABCEMP" + employeeID). This type of key helps in various scenarios, like when one wants to create a higher scale of unique partitions, a lack of uniqueness within single metadata, or a need to distribute the partition as per specific organization policy, and so on.
No comments:
Post a Comment