Hierarchical partition keys are now available in private preview for the Azure Cosmos DB Core (SQL) API. With hierarchical partition keys, also known as sub-partitioning, you can now natively partition your container with up to three levels of partition keys. This enables more optimal partitioning strategies for multi-tenant scenarios or workloads that would otherwise use synthetic partition keys. Instead of having to choose a single partition key – which often leads to performance trade-offs – you can now use up to three keys to further sub-partition your data, enabling more optimal data distribution and higher scale.
For example, if you have a scenario with 1000 tenants of varying sizes and use a synthetic partition key of TenantId_UserId, you can now natively set TenantId and UserId as your hierarchical partition keys.
Behind the scenes, Azure Cosmos DB will automatically distribute your data among physical partitions such that a logical partition prefix (e.g. Tenant) can exceed 20GB of storage. In addition, queries that target a prefix of the full partition key path are efficiently routed to the subset of relevant physical partitions.
Example scenario
Suppose you have a multi-tenant scenario where you store event (for example, login, clickstream, payment, etc) information for users in each tenant. Some tenants are very large with thousands of users, while the majority are smaller with a few users.
{
“id”: “8eec87e2-2bed-4417-96a6-b2a4b9fbeedc”,
“EventId”: “8eec87e2-2bed-4417-96a6-b2a4b9fbeedc”,
“EventType”: “Login”,
“UserId”: “Marjolaine_Mayer14”,
“Date”: “2020-08-25”,
“TenantId”: “Microsoft”,
“Timestamp”: “2020-08-25T16:18:58.3724648-07:00”
}
We have these operations as part of our data access pattern:
Write operations
- Insert data for each login event
Read operations
- Get all data for a particular tenant
- Get all data for a particular user in a tenant
- Read a single event for a user in a tenant
What should our partition key be?
Let’s look at our options when we are only able to choose one partition key. Then, we’ll see how we can use hierarchical partition keys to achieve an optimal partitioning strategy.
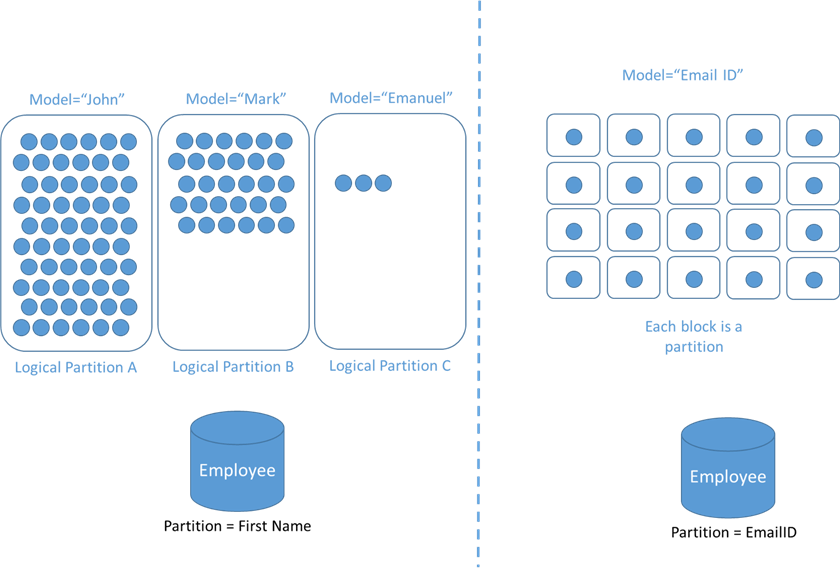
As a refresher, Azure Cosmos DB distributes your data across logical and physical partitions based on your partition key to enable horizontal scaling. As data gets written, Azure Cosmos DB uses the hash of the partition key value to determine which logical and physical partition the data lives on.
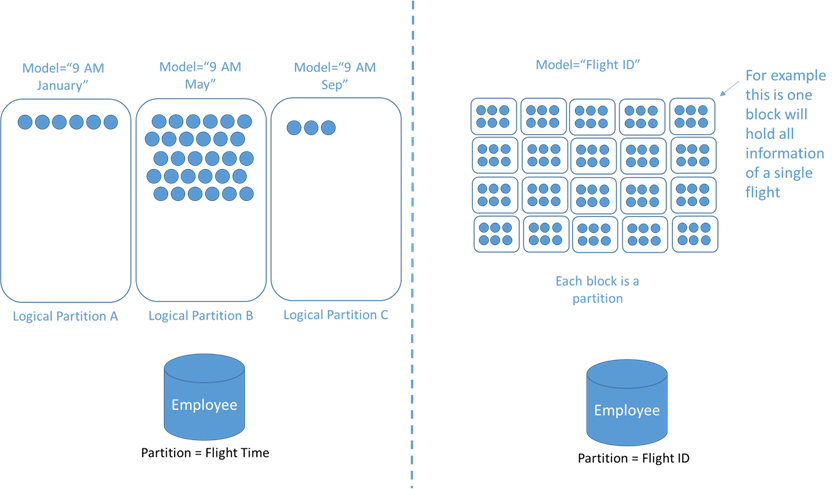
In the following diagrams, the purple boxes represent a physical partition, and the blue boxes represent a logical partition. The scope of the diagram is for a single container.
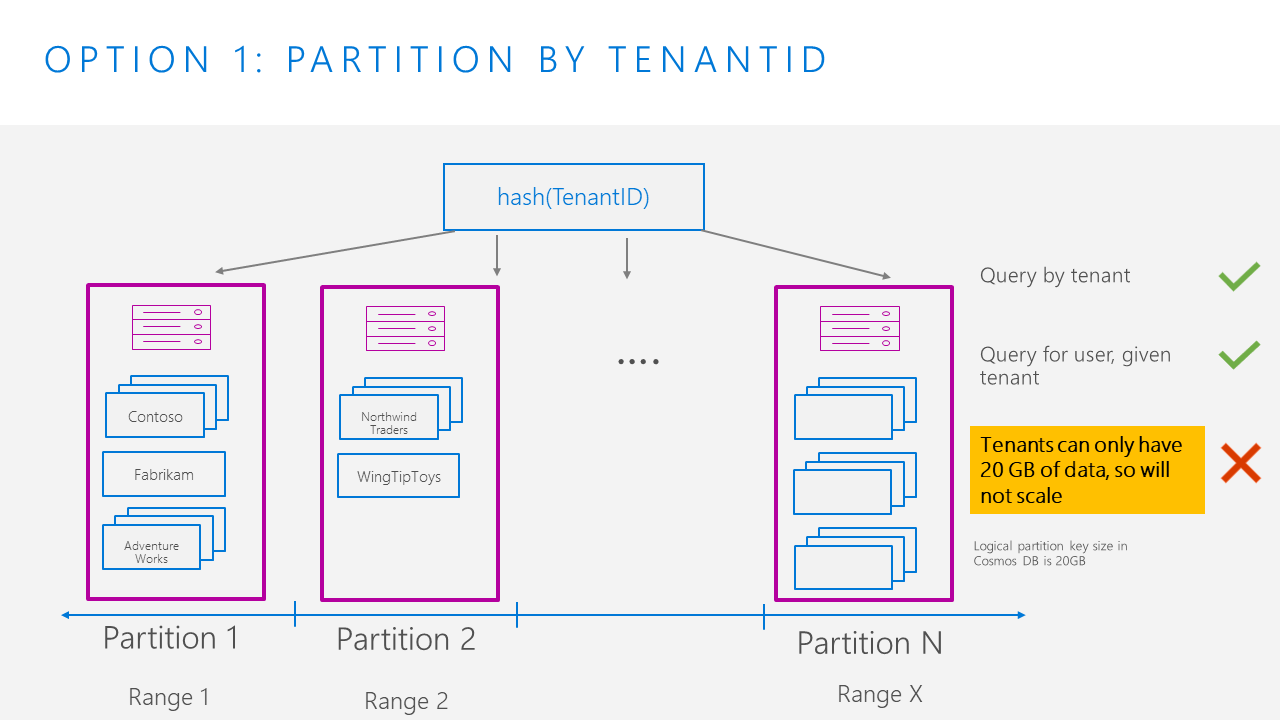
Option 1: Partition by TenantId
When we partition by TenantId, queries for a tenant or a user in a tenant are efficient, single partition queries. However, if a single TenantId grows very large, it will hit the 20GB storage limit for logical partition, so this partition key strategy will not scale. In addition, because some tenants may have more requests than others, this can lead to a hot partition.
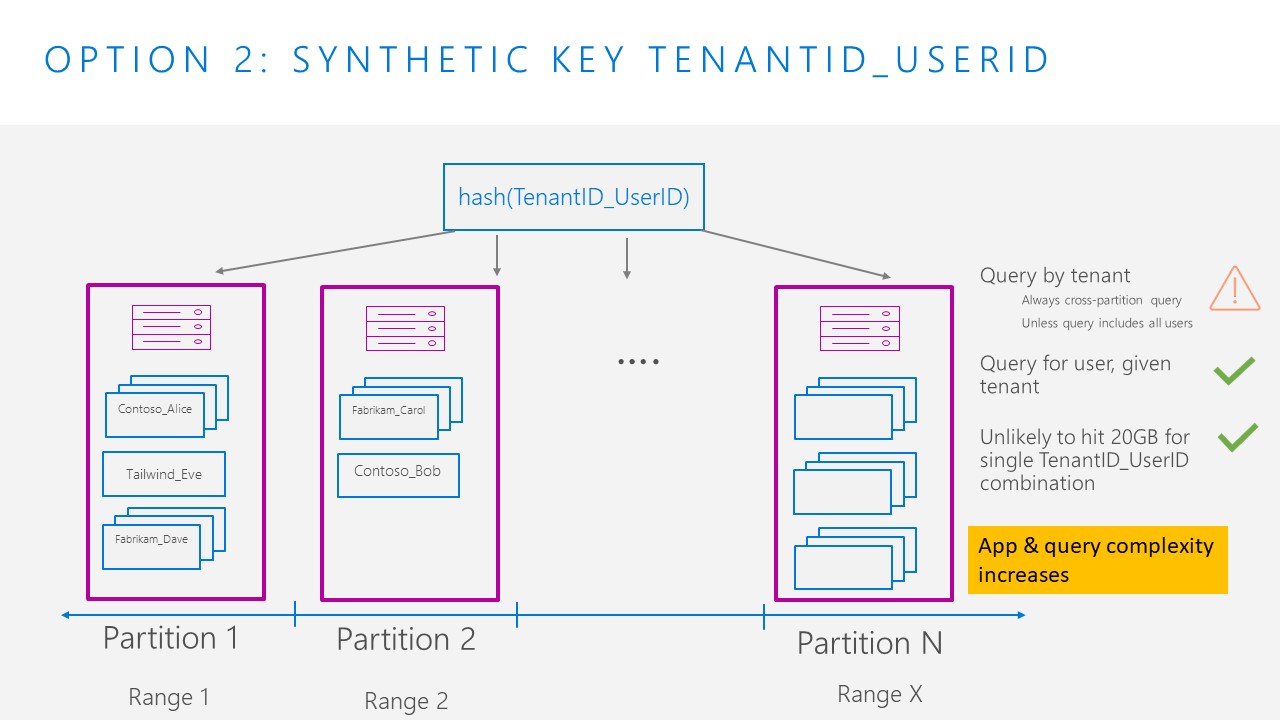
Option 2: Synthetic key with TenantId_UserId
To add more cardinality to our key, we can use a synthetic key, combining TenantId and UserId. Typically, this is done by creating a new property in our document, for example, “partitionKey” and modifying our application logic to fill this value with our synthetic value. While we can ensure that we can write more than 20GB of data per tenant, we now have a trade-off where queries by TenantId are always cross partition, unless we are able to include all users, which is typically not feasible. In general, the application and query complexity has increased.
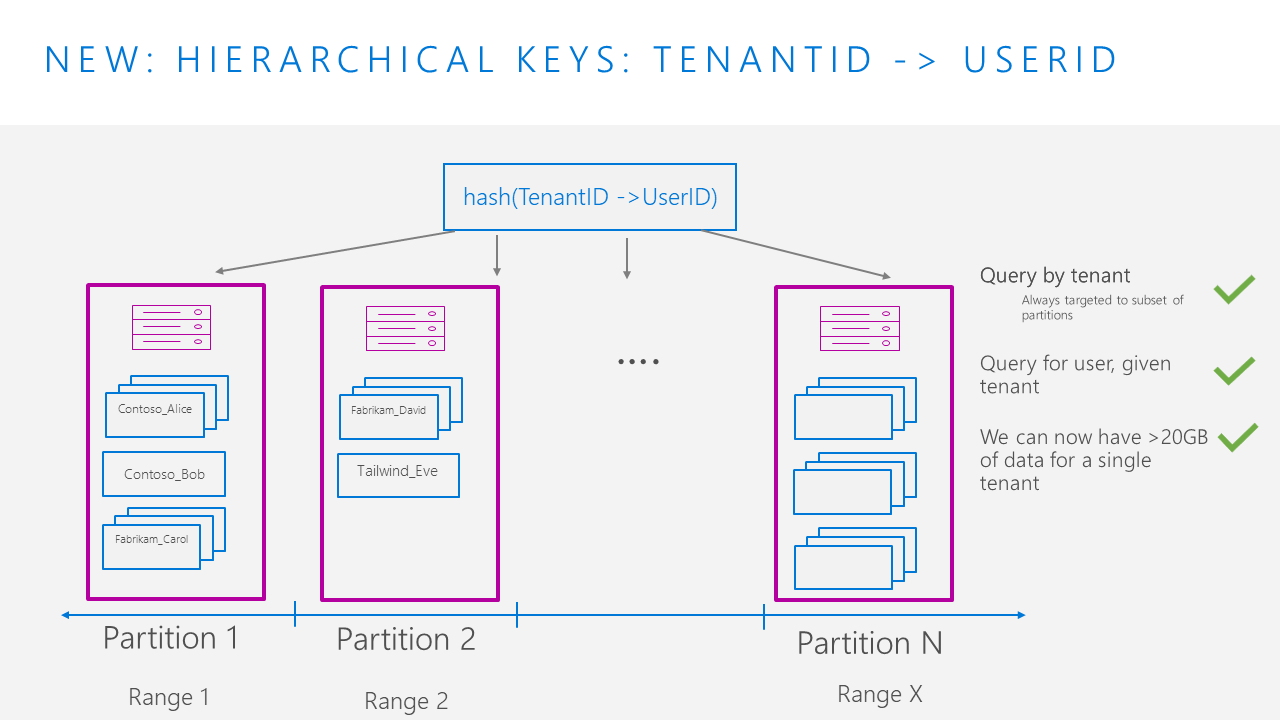
New: Partition using hierarchical partition keys
With hierarchical partition keys, we can set the partition key to be TenantId, then UserId. If we believe the combination of a single TenantId and UserId will exceed 20GB, we could use a 3rd key – e.g. set to something like id or EventId – to add more granularity.
This allows us to have more than 20GB of data for a single tenant, as the system handles adding more partitions as our data per tenant grows. We are now able to have up to 20GB of data for each TenantId, UserId combination. As a result, it is now possible for a single Tenant’s data to span multiple physical partitions.
At the same time, our queries will still be efficient. All queries that target a single tenant will be efficiently routed to the subset of partitions the data is on, avoiding the full cross-partition fanout query that was required when using the synthetic partition key strategy. For example, in the below diagram, queries that filtered to TenantId = “Fabrikam” would be routed only to partitions 1 and 2.
To achieve these benefits, all we need to do is specify the hierarchical partition key settings upon container creation and ensure these keys exist in all documents. Azure Cosmos DB will take care of the underlying data distribution and query routing.